Data-driven savings
Jason Knuth
Do more, with less. It sounds simple enough and is essential in today’s market, but is it really possible for a mining operation to cut costs without sacrificing productivity? Thanks to the rapidly growing base of connected products known as the Internet of Things (IoT), optimising mine performance to drive down costs per tonne is now more achievable than ever.
The amount of data flowing off mining machines has grown significantly in recent years. Joy Global’s connected products worldwide now stream more than 60 000+ data points per second – more than double what was measurable just a few years ago. In the next five years, it is anticipated that number will grow to half a million data points per second.
This surge of data is the result of several factors, including advances in network communications, cloud-based computing and smarter equipment. The objective is to get actionable information to the end user faster, quickly closing the loop between machine and owner/operator.
Doubling the available information does nothing if the systems cannot keep up. IoT is evolving the big data market, changing the game. It is the company’s enabler to expand and leverage machine knowledge and expertise using larger, more powerful platforms able to ingest increasing amounts of data. These platforms allow the data to be federated across many commodity servers for redundancy and faster retrieval. The servers are designed to operate in parallel, which makes the system easily scalable.
IoT, cloud computing and big data are in the realm of trendy buzzwords. But they also offer real solutions, allowing machines to connect to the internet and each other, as well as making the data accessible in a timely matter. Old data tells a story, but live data paints an actionable picture. With the new technology and computing power, projecting what could happen is a reality. And the faster data comes off the machines, is analysed and turned into useful information, the more quickly mines can react, heading off potential delays and preventing costly downtime.But acting quickly requires trusting the information, essentially, trusting the machines. Joy Global engineers employ machine learning methods to continually improve the accuracy of the data that drives cost-saving decisions.
Analytics focus
Machine learning is a method of analytic concepts. The ‘machine’ in machine learning is not the same machine used to mine minerals; it is a computer. The methods used teach the computer pattern recognition, allowing the computer to search the data for anomalies and report on subtle changes that could be cause for concern.
Machine learning can be broken down into two groups of training: supervised and unsupervised learning. Supervised learning is presenting the computer with a scenario and the desired output – essentially teaching the computer right from wrong at the outset. It can be a time-consuming process with only a few machines but, with enough training sets, the computer becomes more accurate. When the computer gets the answer wrong, it can be told the correct answer so the next time the situation is presented the solution is correct. This approach works best when there is strong engagement with the end user, who can alert Joy of any false alarms and allow the company to quickly instruct the computer for improvement. By teaching the computer to more accurately understand what ‘good’ or ‘normal’ operation looks like, it is less likely to produce false alarms, enabling faster action on the real concerns.
Unsupervised learning is what it sounds like: feeding the computer a large amount of data without labels and letting the computer find hidden patterns and associations. Approaches that leverage this type of learning include clustering, anomaly detection and neural networks. This technique can be advantageous because it finds relationships between data and non-obvious associations. A simple yet powerful example is tracking the temperature of bearings within a transmission. The temperature between bearings will trend together; monitoring that relationship has been used to successfully prevent failures from occurring.
Figure 1 shows an example of how multiple data points in a functional area correlate. The shape/type of correlation between different data sets is not constant: some show a linear trend, while others group to form a cluster. The red dots within each miniplot note a failure. Some correlation pairs highlight the failure, while others mask it. Through the power of machine learning, thousands of models can be run, looking for the times when the data deviates from normal. This example shows paired correlations for ease of viewing in 2D. For more complex relationships, principal component analysis is employed, which transforms the data into multiple dimensions using all of the relationships between the data to align the data in multiple axis, while minimising deviations. This technique highlights when data points diverge from normal.

Figure 1. A plot matrix shows relationships between multiple metrics in a 2D view.
Figure 2 shows a clustering of two variables for a specific machine just before a failure. The ellipses represent the deviation from the centroid of the cluster, at 1, 2 and 3 sigma, which help represent normal operation. As seen in this example, 68%, 95% and 99.7% of the normal data falls within those ellipses, which leaves a grey area of 0.3% of other normal operation that is not typical. This is the point at which a consideration would be made to tune the models, to improve the machine to alert on actual causes for concern, instead of non-typical but normal operations.
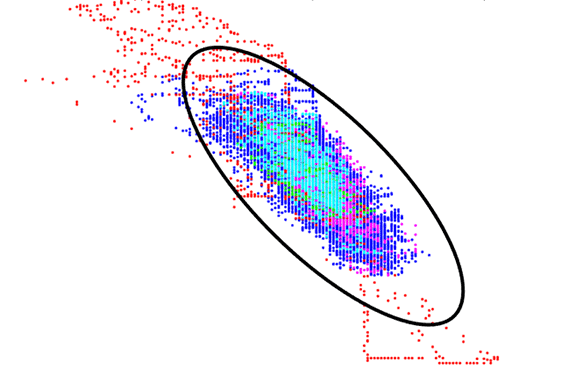
Figure 2. Data tracked over an extended period of time begins to reveal deviations from the centroid.
Case study: Australia
An in-the-field example of the above machine learning relationships in practice can be found in Australia, where Joy Global teams were tasked with improving machine reliability and avoiding catastrophic failures of major components on P&H rope shovels at a coal mine. The mining customer’s maintenance strategies were producing good availability results but, to achieve consistency, the customer wanted better visibility on potential upcoming causes of downtime. In this tough environment, major component failure events needed to be controlled to minimise impact against budget. A data-driven solution was sought to improve margins and maximise shovel operation.
The strategy was to build on Joy’s existing partnership with the mine by employing new technologies and concepts as part of its JoySmart Solutions, designed to help achieve or exceed operating goals. JoySmart product specialists quickly identified areas of focus that would be prioritised to achieve improved reliability. Major equipment monitoring (of motors, transmissions, gearing and bearings) provided the necessary risk management element, while air supply and lubrication were identified as systems that had the most impact on shovel reliability.
Joy proposed and implemented multiple machine learning methods that were automated to monitor incoming machine data with the ability to detect any changes in component behaviour to predict an onset of failure. Creating an algorithm that was sensitive enough to pick up small changes in component indicators, while not creating unnecessary alarms, was key. These algorithms were tuned to the specific machine, as each mine and mining application is different.
On a daily basis, JoySmart product specialists would intercept any model detections and then report out with a recommended course of action, giving it a priority rating depending on the component type and severity of the detection.
Learning to trust the machines required a change in culture however, which was a final hurdle to success. In the first two months of implementation, a situation arose where an imminent failure condition was detected and reported. Figure 3 shows the relationship between bearing temperatures within a functional location. A model of the temperature relation between the bearings showed deviation between the reality and normal operation. The grey dots represent the normal bearing temperature during operation based on the black dots. The red dots represent actual temperature readings that were deviating beyond the statistical intervals.

Figure 3. A model of the temperature relation between the bearings showed deviation between reality and normal operation.
Days before, the system had been alerted to significant divergence between the model and reality to identify this impending issue. But not all recommended steps were followed, resulting in 38 hrs of downtime that could have been avoided. Following that incident, team engagement, trust and commitment rose, allowing for quicker action to be taken going forward.
Employing machine learning, Joy was able to detect abnormal behaviours in the data before the conventional fault systems on the equipment. As demonstrated in Figure 4, anomalies to the black or normal data points were spotted before (in this case, five days) failure and the teams reacted quickly. Driven by data, quick decisions eventually achieved strong results: during the six month trial period, the combined shovel availabilities hit the target of 92% eight weeks in a row and no major equipment failed.

Figure 4. Joy Global analytics experts can spot anomalies (seen in coloured data points) days before the machine control system will alarm.
Case study: USA
In another example, machine monitoring on a 4200 ft Joy underground-to-surface conveyor system at an Illinois coal operation helped prevent catastrophic damage to 4 x 2500 hp gearbox shaft assemblies, which are long lead time items.During commissioning of the system, Joy Global teams took baseline readings to enable flawless startup. Figure 5 shows a map of the torque with respect to vibration that was used for the baseline readings. The blue line represents average vibration signature during start up for that specific conveyor. When the system was in regular operation and excessive startup torque was detected, the company’s crews used those baseline readings to quickly target the problem area.

Figure. 5. A map of the torque with respect to vibration signature during start up for a specific conveyor gearbox.
Personnel then immediately went to the site to investigate the problem area with handheld vibration monitors and confirmed there was excessive vibration on the head drive pulley due to a faulty coupling. Normal production was able to continue, while the company monitored the anomaly and determined how to resolve the problem and prevent damage to the gearboxes.
As a result, none of the four gearboxes were damaged by the faulty coupling, saving the customer months of costly downtime. The issue was fixed during a scheduled maintenance period, eliminating the need for any unplanned downtime and allowing nonstop production at the site.
Conclusion
Through continued machine learning and evolving technology capabilities, such as faster and more reliable networks, the opportunities to use data to drive down operational costs – by reducing or eliminating downtime and increasing productivity – will only continue to grow. What if the same amount of material could be mined in two shifts instead of three, simply by reducing avoidable delays? This is possible through monitoring and informed decision making.Machine learning capabilities and algorithms grow more accurate with each challenge that is solved. As these algorithms become more reliable, constant and customer accepted, they also will be incorporated into the basics of the machine.
Working together with the machines and its customers, Joy Global is steadily improving the flow of data and the speed at which it translates that into actionable information, allowing operators to do more, with less, without sacrificing quality.
About the author: Jason Knuth is a Senior Prognostics Engineer at Joy Global.
This article first appeared in the September issue of World Coal.
Read the article online at: https://www.worldcoal.com/special-reports/14092016/data-driven-savings-joy-global-jason-knuth-2016-2425/
You might also like


SECMC's digital transformation journey
SECMC is leveraging digital technologies, AI, automation, and data-driven decision-making to enhance safety, productivity, and sustainability in Pakistan's pioneering opencast coal mine.